《C++程序设计》阅读笔记【1-函数】



🌈个人主页:godspeed_lucip 🔥 系列专栏:《C++程序设计》阅读笔记
@TOC
1 函数
1.1 概述
C++必须知道函数的返回类型以及接受的参数个数和类型。这也就是为什么当函数的定义出现在函数调用之后时,就必须在程序的开始部分用函数原型进行说明。
如果函数返回的是其他的基本数据类型,则在返回时,先进行隐式的类型转换,然后再返回(自定义的数据类型也是不可以进行转换的)
return(3)和return 3是等价的
1.2 函数定义、声明、原型
-
函数定义(Function Definition):
- 函数定义包括实际的函数实现,也就是函数体(包含执行的代码块)。
- 函数定义提供了函数的详细实现,告诉编译器如何执行函数。
- 一个程序中可以有多个函数定义,但每个函数只能有一个定义。
- 通常位于源文件(.cpp)中。
int add(int a, int b) { return a + b; } -
函数声明(Function Declaration):
- 函数声明是告诉编译器该函数的存在,但不提供具体的实现。
- 用于在调用函数之前向编译器提供有关函数的信息,包括函数名称、返回类型和参数列表。
- 通常在头文件中进行函数声明,以便在不同源文件中使用。
int add(int a, int b); -
函数原型(Function Prototype):
- 函数原型是函数声明的另一种术语,通常指的是提供了函数的名称、返回类型和参数列表,但没有具体的实现。
- 与函数声明相似,函数原型也用于告诉编译器有关函数的信息。
- 在函数定义之前,可以在同一个文件中提供函数原型,以便在文件中的其他位置使用。
int add(int a, int b);
函数原型中,下面两行代码是等价的:
void Area(double width, double length);
void Area(double, double);
它们都提供了函数原型所需要的所有信息
在C++中,函数声明就是函数原型
1.3 变量
程序在内存中的分布:

根据变量定义,全局变量和静态变量在定义(分配空间)时,将位模式清0;局部变量在定义时,分配的内存空间内容保持原样,故为随机数。这也就是为什么全局变量和静态变量的默认值为0。
1.3.1 全局变量
存放在全局区
如果全局变量在代码中不被初始化,则编译器会自动初始化为0。
注意全局静态变量和全局变量的不同:
全局静态变量只在本文件可见,其他文件不可见。而全局变量可以通过链接的方式让其他文件可见。它们的初始化规则都是一样的。
1.3.2 局部变量
存放在栈区
局部变量的类型修饰是auto,表示该变量在栈中分配空间,但是一般省略auto。例如
int n;
auto int n;
//这两句是等价的
如果局部变量不被初始化,那么它的值是不可预料的
P84例子见下面的解释
1.3.3 静态局部变量
存放在内存的全局数据区。初始化规则与全局变量一致。
虽然存放在全局区,但是它只在定义它的函数中可见。
例如:看程序写结果

结果:

1.4 函数调用机制
在如图所示的例子中:

其栈空间使用示意图是这样的:

funcB和funcA都返回后,funcA函数和funcB函数开辟的栈空间都归main函数所有,且内存中的数据并没有变化。
这是因为当函数funcA调用函数funcB时,funcA的栈帧会被保存在调用栈上,包括局部变量、参数、返回地址等。当函数funcB执行完毕后,funcB的栈帧会被销毁,控制权回到函数funcA的栈帧。此时,函数funcA的局部变量依然存在于栈上。
只有当函数funcA的执行完全结束,包括其所有嵌套的函数调用,funcA的栈帧才会被销毁,局部变量才会被释放。所以,函数funcA初始化的局部变量在funcA执行结束之前会一直存在于栈上。
所以此时的栈开空间使用情况图如下:

因此,可以想象,当有局部变量没有初始化时,且恰好编译器为局部变量开辟的是被初始化过且还没有来得及被释放的内存地址,那么该局部变量的值就是不可预料的。
1.5 函数递归
递归函数可以没有返回值
求最大公约数的递归与非递归版本:

1.6 内联函数
内联函数是一种编译器优化技术,它的目标是在不引入函数调用的开销的情况下,将函数的代码嵌入到调用处,以提高程序的执行效率。编译器会尝试将函数的代码插入到调用处,而不是生成一个实际的函数调用。
我的理解:为了提高可读性(以函数的形式),同时又降低了开销(不会发生调用,而是会将函数作为代码嵌入进去)
格式:
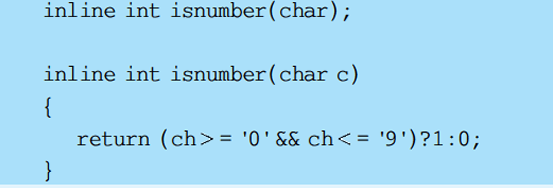
内联函数中不能含有复杂的结构控制语句,如switch 和 while。如果内联函数有这些语句,则编译将该雨数视同普通函数那样产生函数调用代码。
1.7 重载函数
重载时,编译器匹配函数的顺序:

函数重载时有时会发生自动类型转换,这就要求转换不能有二义性,例如:

在使用print函数打印一个int型时,应该给予一个显示的类型转换
重载函数至少在参数个数、参数类型或参数顺序上有所不同。
1.8 默认参数的函数
1.8.1 定义的规则
默认参数在函数声明中提供,当又有声明又有定义时,定义中不允许默认参数。如果函数只有定义,则默认参数才可出现在函数定义中。
chatGPT的解释:
说实话,还是有点不理解。
对于具有默认参数的函数,编译器会生成包含这些默认参数的实现代码。这意味着在编译时,编译器会为带有默认参数的函数生成多个版本,以覆盖各种调用方式。
考虑以下示例:
// 头文件 example.h
#ifndef EXAMPLE_H
#define EXAMPLE_H
int add(int a, int b = 0); // 函数声明
#endif
// 源文件 example.cpp
#include "example.h"
int add(int a, int b) { // 函数定义
return a + b;
}
在这个例子中,如果在某个源文件中调用 add 函数时不提供第二个参数,编译器会在编译时生成一个版本,将默认参数 b = 0 包含在内。这个版本的代码将使用默认参数的值来执行函数。
如果在另一个源文件中调用 add 函数时提供了第二个参数,那么编译器会生成另一个版本,使用提供的参数值来执行函数。因此,编译器为每个可能的调用情况生成一个相应的版本。
这种方式确保了默认参数在编译时能够被正确地处理,同时也解释了为什么在函数声明中提供默认参数信息,而在函数定义中不提供默认参数的实现代码。在调用时,编译器会根据实际的调用情况选择合适的函数版本。
1.8.2 和重载函数
默认参数也可以用来将一系列重载函数合成为一个函数

1.8.3 默认值的限定
默认值可以为全局变量、全局常量、函数(只要能够在编译时确定就ok)。但是其值不可以是局部变量
2 总结
C++,犹如编程的交响乐, 在代码的海洋中奏响和谐的旋律。
它是创造者的笔,雕刻着无尽可能,
是思想的翅膀,让梦想飞翔的天空。
无拘无束,灵活多变。
C++,是程序员心中的宝藏,永不凋零的花朵。
渴望挑战C++的学习路径和掌握进阶技术?不妨点击下方链接,一同探讨更多C++的奇迹吧。我们推出了引领趋势的💻C++专栏:《C++程序设计》阅读笔记,旨在深度探索C++的实际应用和创新。🌐🔍

